User guide
Introduction
The user interface of AgileQualityFilter is shown in Figure 1, and consists of a number of user-selectable inputs. A choice must be made for each input, except the optional Filter by tags, before the data can be processed.
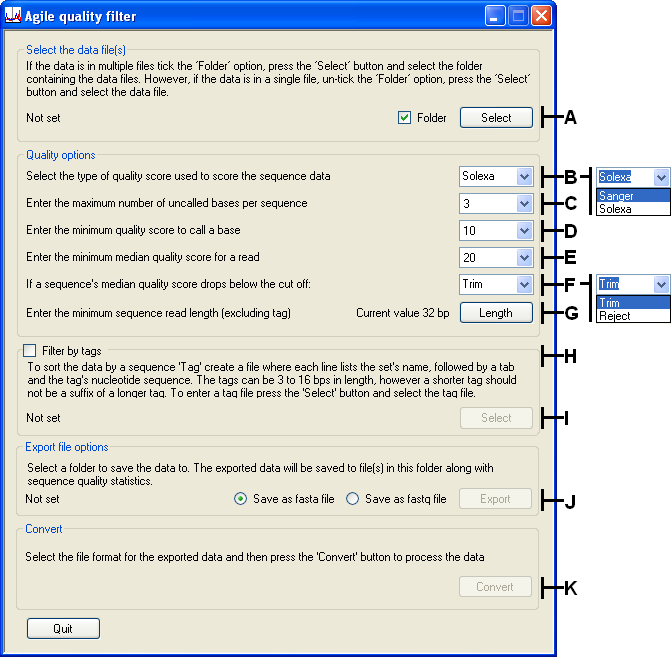
Figure 1: AgileQualityFilter user interface
Selecting data
The upper panel Select the data file(s) allows the user to select the sequence data as either a single file (*_qseq.txt or *.fastq) or a folder of such files. If a folder is selected which contains both types of file, the program will prompt the user to choose which file type to use; AgileQualityFilter will not combine data from different file types. If a folder of sequence data is to be filtered, tick the box next to the button (labelled A in Figure 1). Then select the data by pressing the button and navigate to the folder. If only a single file is to be filtered, untick the box, press and choose the data file.
Setting the filter options
The field allows the user to set the filtering parameters used by AgileQualityFilter.
- (B in Figure 1) defines whether Solexa- or Sanger-type quality scores are used in the data files.
- (C in Figure 1). If a read contains more uncalled positions than the cut-off value selected here, the read will be truncated. For example, if the cut-off is set at 3 but a read contains 5 uncalled bases, the 3′ part of the read starting at (and including) the fourth misscalled position will be discarded.
- (D in Figure 1) sets the minimum quality score a position must have for it to be called. When a residue’s quality score falls below this, an N is substituted at this position.
- (E in Figure 1) defines the minimum median quality score a sequence must have to be included in the export file. This value is calculated from the 5′ end of the sequence as it is processed by the program. If a sequence’s median quality score falls below the cut-off it is either discarded or trimmed, depending on whether ‘Trim’ or ‘Reject’ is selected in the next menu (see below).
- (F in Figure 1) toggles whether a sequence is discarded or trimmed, in the event that it fails the test set using the previous option. If it is to be trimmed, the sequence is truncated at the first position where its median quality score falls below the cut-off.
- (G in Figure 1) sets the minimum length of a processed sequence read that will be exported. Reads shorter than this value are discarded.
Processing data containing 5′ tags
If the data contains reads that are “tagged” with a 5′ sequence tag, tick the box (labelled H in Figure 1) to activate this option. Once activated, press the button (I in Figure 1) and choose a tab-delimited plain text file that contains the tag sequences and tag “IDs”. The tags can be between 3 and 16 bp in length, but a shorter tag must not be a suffix to a longer tag. If a read contains a tag, the tag is removed and the read is exported to a file named after the tag’s “ID” value. The tag file format is shown in Table 1; using this tag file would result in the creation of four files, named APC, SATBII, PXDN and ATOH7. All reads that started with the sequence TAA, TAGG or TATTT, would be placed in the appropriate APC, PXDN or ATOH7 file, respectively. Any sequence that started with TAAC, TACC , TAGC or TATC would be placed in the SATBII file.
| Tag ID | Delimiter | Tag sequence |
|---|---|---|
| APC | <tab space> | TAA |
| SATBII | <tab space> | TANC |
| PXDN | <tab space> | TAGG |
| ATOH7 | <tab space> | TATTT |
Export file location
The location to which exported data are saved is selected using the button (J in Figure 1), in the Export file options field. This field also contains the and options, which allow the format of the exported data to be selected.
Processing the data
Once the data file and export file have been entered, the button (K in Figure 1) will be activated. Pressing this button will start the filtering process and the creation of the export file(s), along with two summary files. The DataLog<current date>(<current time>).xls file contains information on the files processed and the cut-off values used in the filtering. The ReadStats.xls file contains a summary of the number of reads at each position and their average quaility score before and after filtering. Examples of these files can be found here.